12 N
12.1 Talking Glossary: Non-coding DNA (1 min)
Abstract: “Non-coding DNA sequences do not code for amino acids. Most non-coding DNA lies between genes on the chromosome and has no known function. Other non-coding DNA, called introns, is found within genes. Some non-coding DNA plays a role in the regulation of gene expression.”
Note: Non-coding DNA (previously called junk DNA) makes up 98% of the genome. It is very useful for evolutionary and phylogenetic studies because it is not directly impacted by natural selection.
Transcript: “Non-coding DNA is just what it says; it’s non-coding DNA. You can think of the genome as being split up into two parts. There’s the stuff that codes for proteins. We call it coding DNA, and for a lack of a better term, the rest of genome is referred to as non-coding DNA. Some people will like to try and refer to this as junk DNA. But I would suggest otherwise, because this represents 98 percent of our genome sequence and it does all sorts of things, like regulate those genes to figure out where they should turn on, where they should turn off, how much we should turn on certain genes, how are we going to pack up the DNA into chromosomes, and so forth. And there are probably a whole host of functions that non-coding DNA does that we still don’t know what it does yet.”
Elliott Margulies, Ph.D.
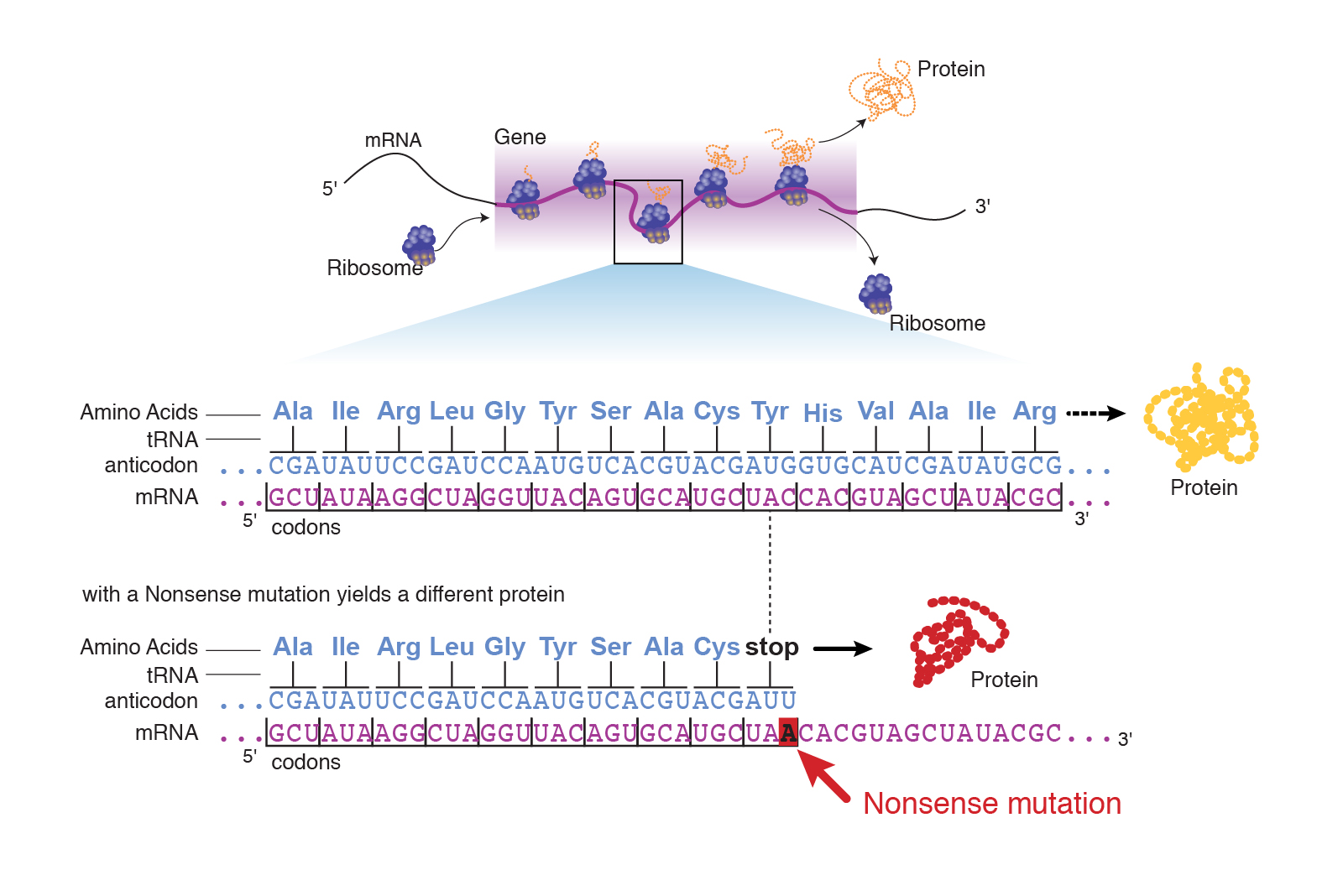
12.2 Talking Glossary: Nonsene mutation
https://www.genome.gov/genetics-glossary/Nonsense-Mutation
Abstract: “A nonsense mutation is the substitution of a single base pair that leads to the appearance of a stop codon where previously there was a codon specifying an amino acid. The presence of this premature stop codon results in the production of a shortened, and likely nonfunctional, protein.”
Audio: https://www.genome.gov/sites/default/files/tg/en/narration/nonsense_mutation.mp3
Image: https://www.genome.gov/sites/default/files/tg/en/illustration/nonsense_mutation.jpg
{kind=link}
Transcript
“A nonsense mutation, or its synonym, a stop mutation, is a change in DNA that causes a protein to terminate or end its translation earlier than expected. This is a common form of mutation in humans and in other animals that causes a shortened or nonfunctional protein to be expressed.”
Leslie G. Biesecker, M.D.
12.3 Nucleic Acids - Overview
Authors: OpenStax / Libretext Formatted in RMarkdown by Nathan Brouwer under the Creative Commons Attribution License 4.0 license.
This chapter was adapted from LibreText General Biology, Chapter 3, Section 3.5: Nucleic Acids. The LibreText book is based on OpenStax Biology 2nd edition, Chapter 3, Section 3.5: Nucleic Acids.
Additional material taken from LibreText General Biology, Chapter 3, Section 3.4: Proteins. The LibreText book is based on OpenStax Biology 2nd edition, Chapter 3, Section 3.4: Nucleic Acids.
A full list of authors is found under the Contributors and Attributions section at the end of this document.
12.3.1 DNA and RNA
Nucleic acids are the most important molecules for the continuity of life. They carry the blueprint of a cell and carry instructions for the functioning of cell and organisms. There are two main types of nucleic acids: deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). DNA is the genetic material found in all living organisms, ranging from single-celled bacteria to multicellular mammals.
The entire genetic content of a cell is known as its genome, and the study of genomes is genomics. Many – but not all – genes contain the information to make proteins.
Proteins are one of the most abundant biological molecules in living systems and have a diverse range of functions. Each cell in a living system may contain thousands of proteins, each with a unique function. Their structures, like their functions, vary greatly. They are all, however, polymers of amino acids, arranged in a linear sequence. This sequence is determined by DNA.
DNA molecules don’t directly code for proteins, but rather use an intermediary to communicate with the rest of the cell. This intermediary is messenger RNA (mRNA).
DNA and RNA are made up of single subunits known as nucleotides. The nucleotides combine with each other to form a long chain of either DNA or RNA. The sequences of the nucleotides contains the information to make proteins. In DNA there are four nucleotides: adenine (A), guanine (G) cytosine (C), and thymine (T).
12.3.2 DNA Double-Helix Structure
DNA has a double-helix structure made up of two separate strands of nucleotides. The two strands of the helix run in opposite directions.
Only certain types of base pairing are allowed: A can pair with T, and G can pair with C. This is known as the base complementary rule. In other words, the DNA strands are complementary to each other. If the sequence of one strand is AATTGGCC, the complementary strand would have the sequence TTAACCGG. During DNA replication, each strand is copied, resulting in a new DNA double helix.
12.3.3 RNA
Ribonucleic acid, or RNA, is mainly involved in the process of protein synthesis . RNA is usually single-stranded and is made of ribonucleotides, which are slightly different than nucleotides. RNA can contain adenine, guanine, cytosine, or uracil ribonucleotides. Importantly there is no thymine ribonucleotide - uracil takes its place.
RMA molecules called messenger RNA (mRNA) carry the message from DNA. If a cell requires a certain protein to be synthesized, the gene for this product is turned “on” and the messenger RNA is made using the appropriate DNA as a template. The RNA base sequence is complementary to the coding sequence of the DNA from which it has been copied. However, as just noted, in RNA, the base T is absent and U is present instead. If the DNA strand has a sequence AATTGCGC, the sequence of the complementary RNA is UUAACGCG.
Once mRNA is made is can serve as a template for the synthesis of proteins. Proteins or the primary building blocks of cells and thereby tissues, organs and organisms. For example, muscles are made up of long filaments of large cells containing bundles of proteins.
mRNA is read in sets of three bases known as codons. Each codon codes for a single amino acid. Amino acids are the monomers (subunits) that make up proteins. In this way, the mRNA is read and the protein product is made.
Nucleotides and ribonucleotides are represented by a single letter: A, T, C, G and U. Similarly, amino acids are represented by a single upper case letter or a three-letter abbreviation. For example, valine is known by the letter V or the three-letter code val. The sequence and the number of amino acids ultimately determine a protein’s shape, size, and function.
Information flow in an organism takes place from DNA to RNA to protein. DNA dictates the structure of mRNA in a process known as transcription, and RNA dictates the structure of protein in a process known as translation. This is known as the “Central Dogma” of molecular biology, (though there are important exceptions).
12.3.4 Protein function
The shape of a protein is critical to its function. For example, enzymes bind to other molecules at a site known as their active site. If this active site is altered because of the interference of a chemical such as a drug or toxin, the enzyme may be unable to bind to the substrate. Similarly, a mutation in the DNA that codes for the protein can change the shape of the active site and prevent it from functioning properly.
The unique sequence for every protein is therefore ultimately determined by the gene encoding the protein. A change in nucleotide sequence of the gene’s coding region may lead to a different amino acid being added to the growing polypeptide chain, causing a change in protein structure and function. In condition sickle cell anemia, part of the protein hemoglobin has a single amino acid substitution, causing a change in protein structure and function. Hemoglobin has about 600 amino acids. The structural difference between a normal hemoglobin molecule and a sickle cell molecule – which dramatically decreases life expectancy - is a single amino acid of the 600. What is even more remarkable is that those 600 amino acids are encoded by three nucleotides each, and the mutation is caused by a single base change (point mutation), 1 in 1800 bases. Because of this change of one amino acid in the chain (and 1 nucleotide in the underlying DNA code), hemoglobin molecules form long fibers that distort the normal shape of red blood cells, turning them into a crescent or “sickle” shape, which clogs arteries. This can lead to myriad serious health problems such as breathlessness, dizziness, headaches, and abdominal pain for those affected by this disease.
12.3.5 Summary
Nucleic acids are molecules made up of nucleotides that direct cellular activities such as cell division and protein synthesis. There are two types of nucleic acids: DNA and RNA. DNA carries the genetic blueprint of the cell and is passed on from parents to offspring (in the form of chromosomes). It has a double-helical structure with the two strands running in opposite directions. RNA is single-stranded. RNA provides the template for protein synthesis. Messenger RNA (mRNA) is copied from the DNA and contains information for the construction of proteins.
12.3.6 Glossary
amino acid: monomer of a protein; has a central carbon or alpha
carbon to which an amino group, a carboxyl group, a hydrogen, and an R
group or side deoxyribonucleic acid (DNA): double-helical molecule
that carries the hereditary information of the cell
messenger RNA (mRNA): DNA that carries information from DNA to allow
protein synthesis
nucleic acid: biological molecule that carries the genetic blueprint
of a cell and carries instructions for the functioning of the cell
nucleotide: monomer of nucleic acids; protein: biological
macromolecule composed of one or more chains of amino acids
ribonucleic acid (RNA): single-stranded
molecule that is involved in protein synthesis
transcription: process through which messenger RNA forms on a
template of DNA
translation: process through which RNA directs the formation of
protein
12.3.7 Contributors and Attributions
Connie Rye (East Mississippi Community College), Robert Wise (University of Wisconsin, Oshkosh), Vladimir Jurukovski (Suffolk County Community College), Jean DeSaix (University of North Carolina at Chapel Hill), Jung Choi (Georgia Institute of Technology), Yael Avissar (Rhode Island College) among other contributing authors. Original content by OpenStax (CC BY 4.0; Download for free at http://cnx.org/contents/185cbf87-c72…f21b5eabd@9.87).