10.2 Preliminary step: download a .csv file
To load a .csv file into R we first need a .csv file to load. The data we’ll be working with can be downloaded from GitHub. First, go to the following link (it happens to be an obscure subfolder of the wildlifeR package)
https://github.com/brouwern/wildlifeR/tree/master/inst/extdata
Next, locate the file Medley1998.csv
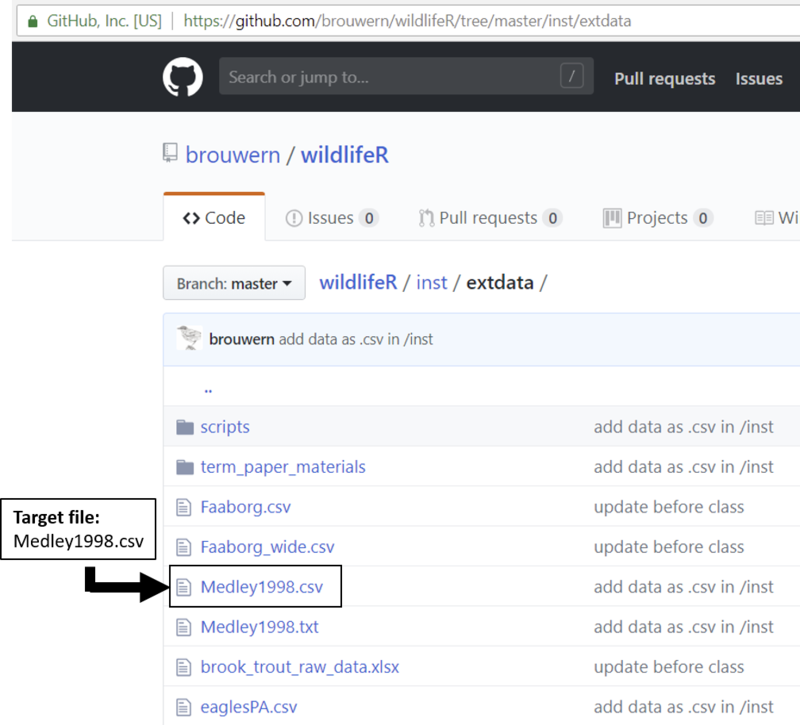
Figure 10.1: A list of files stored on GitHub.
Click on it; a table will show up.
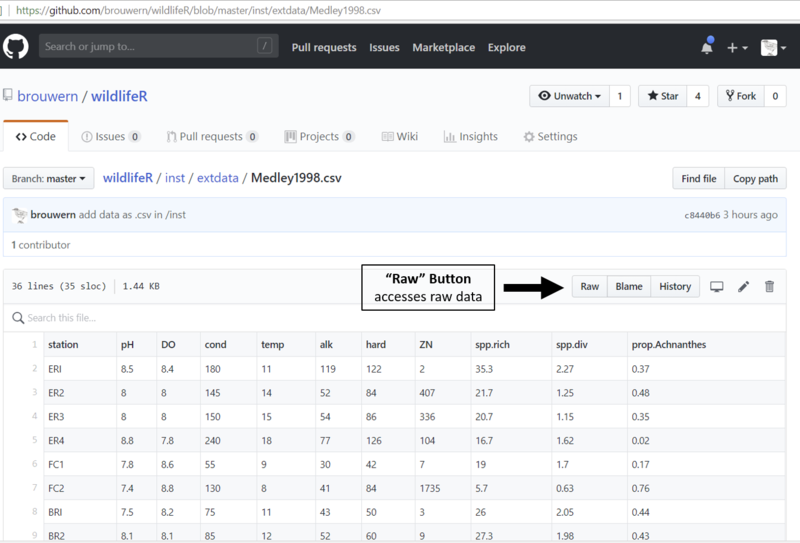
Figure 10.2: An HTML .csv datafile store on GitHub. The raw file can be accessed by clicking on the Raw tab.
This table is formatted to look nice on a webpage (using some HTML that GitHub impose on the file). We want the raw file itself. To get it we need to click on the “Raw” tab.
Figure 10.3: A raw .csv datafile stored on GitHub. It can be downloaded By using Crtl+S or right clicking and selecting Save As
We will then see what looks like a text document against a white background with no formatting of any kind. We can now download the file by following these steps.
Either
- Use the shortcut Control + S to “Save as” the file
Or
- Right click (on Mac:…)
- “Save link as” (or the equivalent)
Then save the file to a location you know you can find, such as
- Documents
- Desktop
- Your network profile drive
Note that if you try to “Save as…” anything else but the white-screen raw text file you will run into problems.
After you download the file, open up Excel or another spreadsheet program and open up the file to confirm that what you downloaded is just a set of numbers. I you see long lines of text you might have accidentally downloaded the HTML-formatted version of the file. Make sure you are downloading the very plain version of the file from the totally blank white screen.